
Research
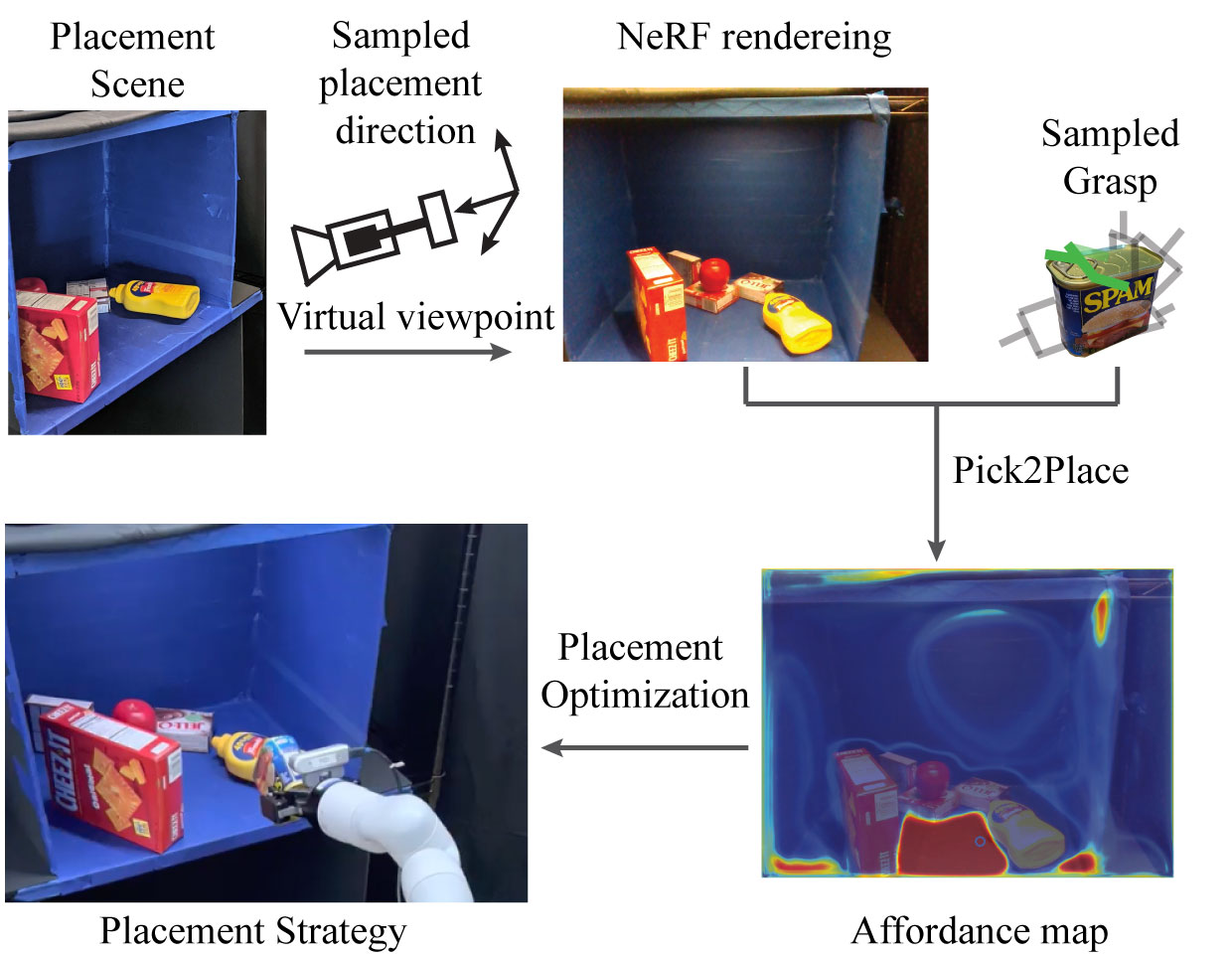
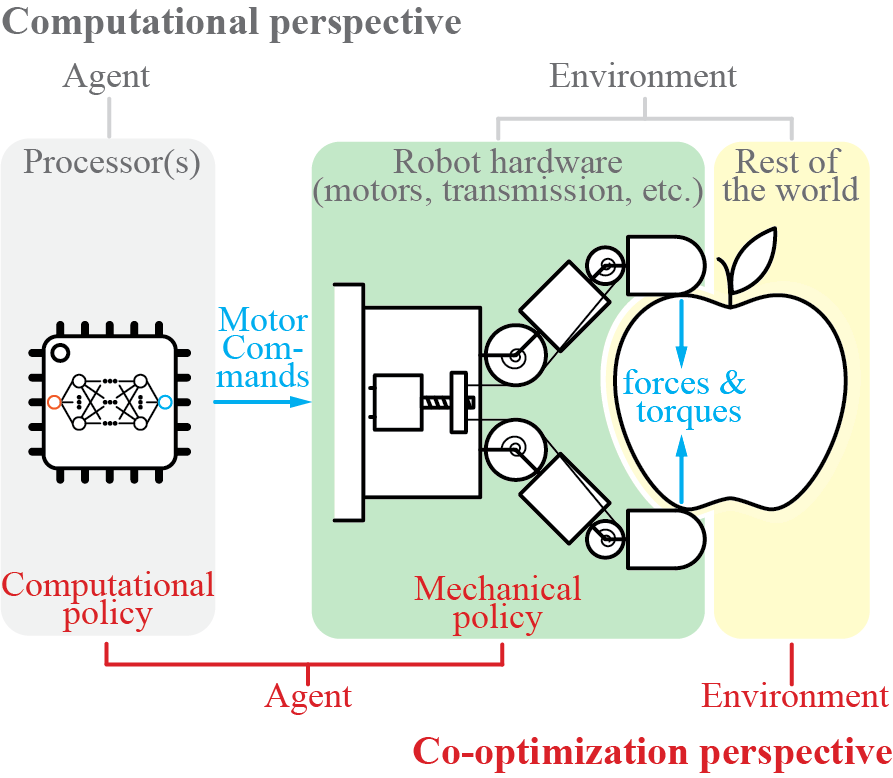
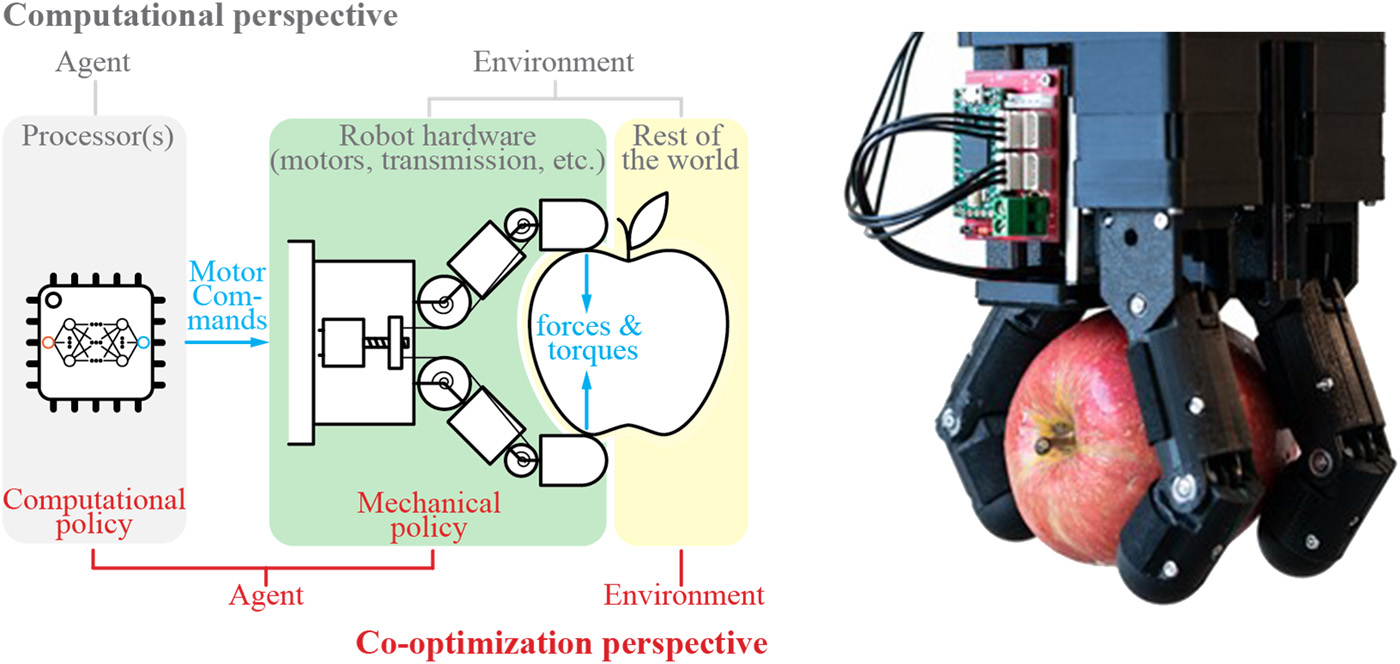
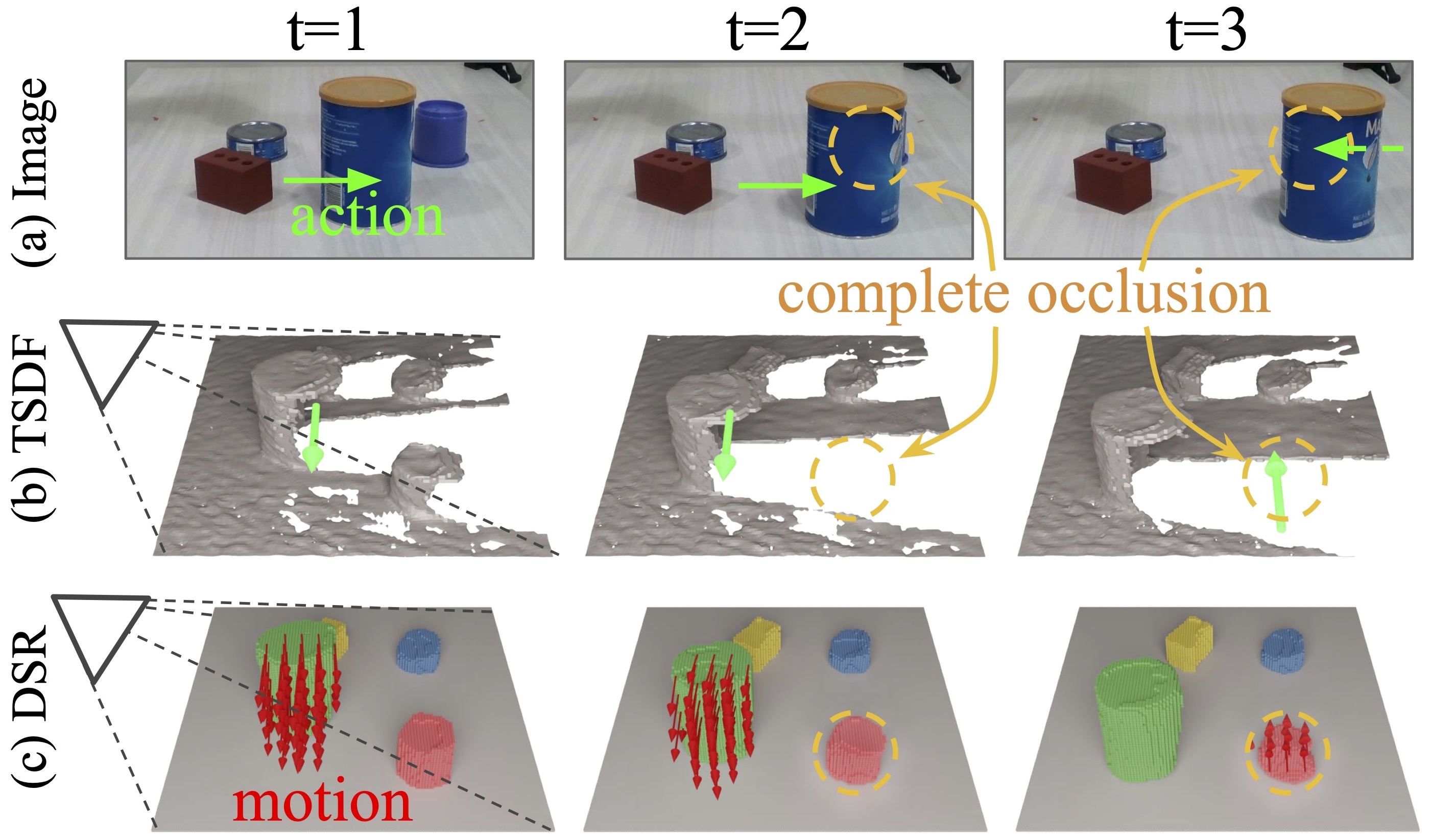
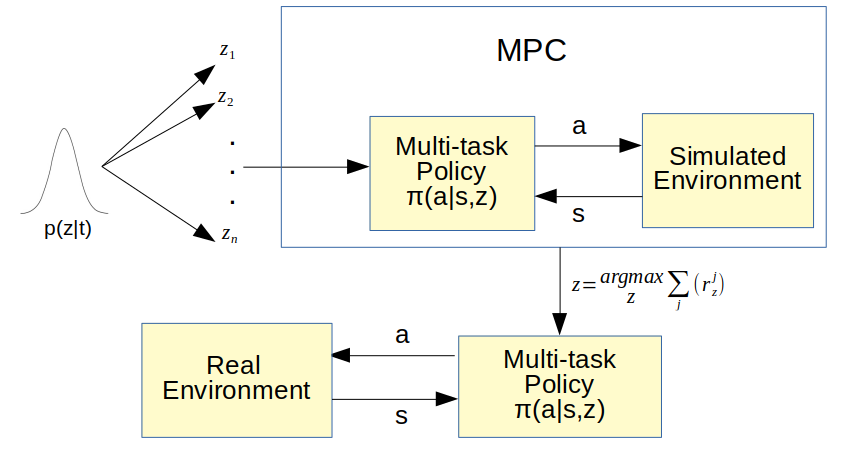
I'm a full-stack roboticist -- I believe robotics must be solved through progress in many different integral components. While scaling up data collection is important, we also need to design the right hardware (e.g, manipulators and contact sensors) and learning algorithms (e.g., learning from imbalanced sensor data) to enable robust policies on real robots for contact-rich tasks. To this end, my research includes:
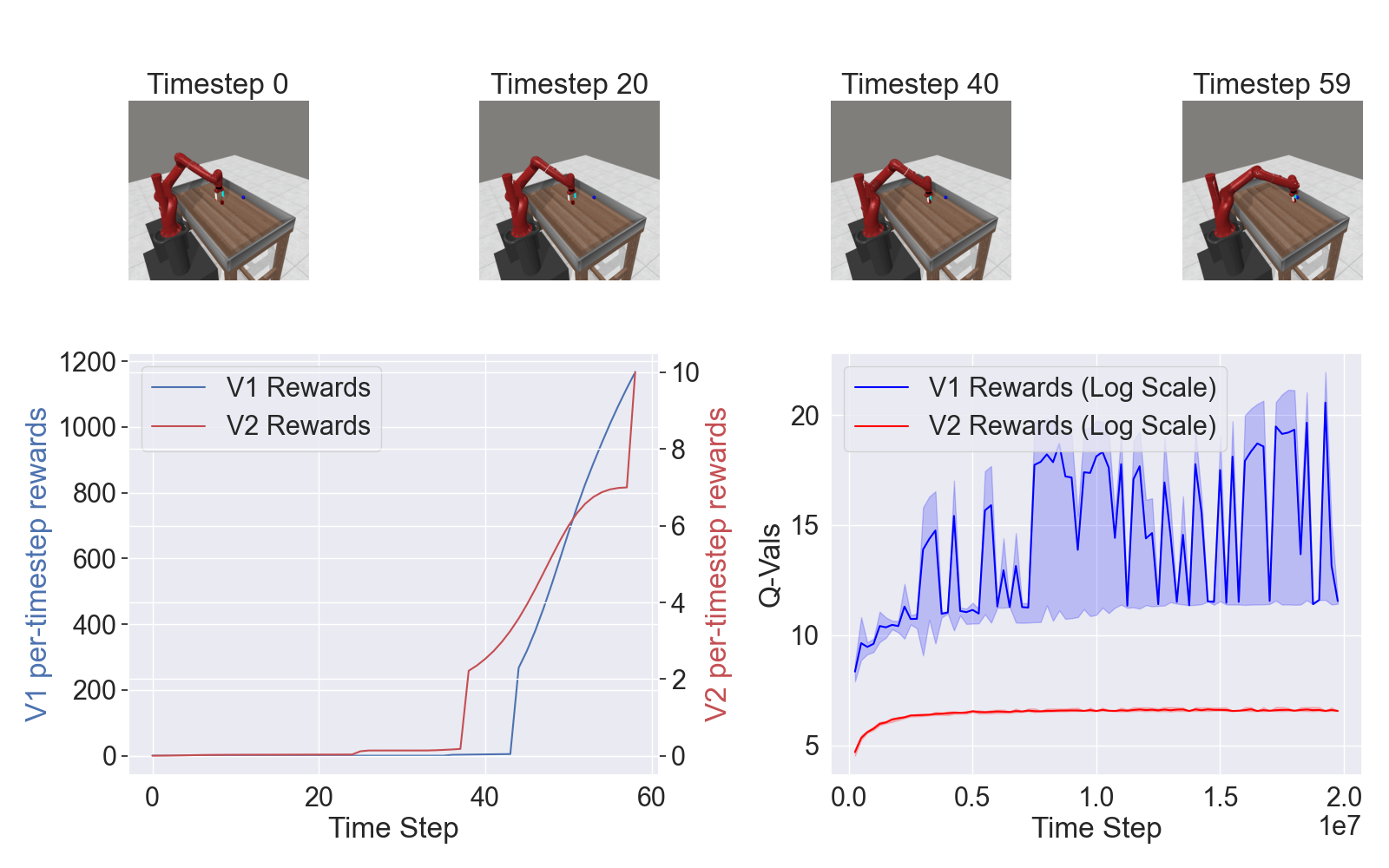
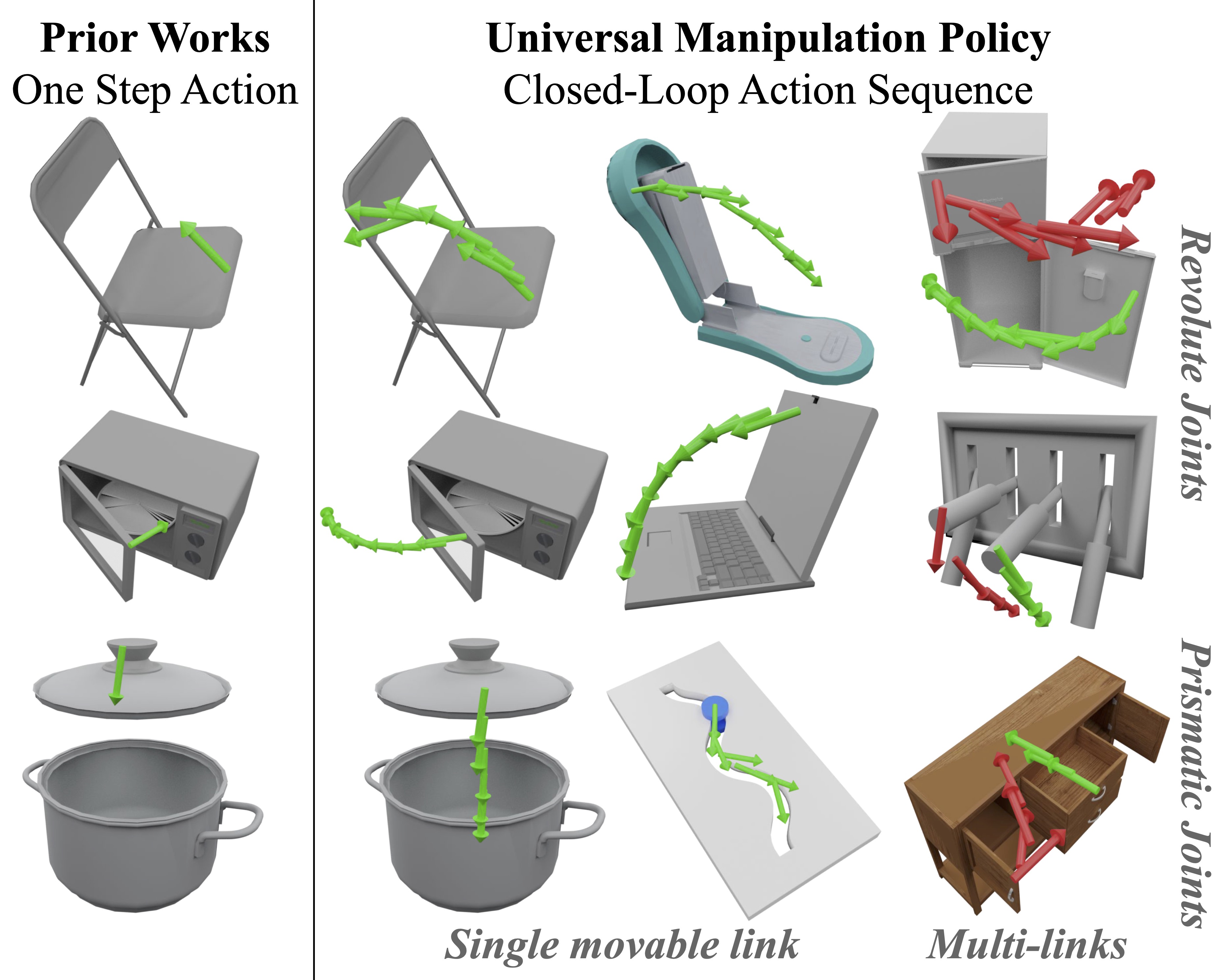
- Policy learning (e.g., imitation learning, reinforcement learning) for contact-rich tasks;
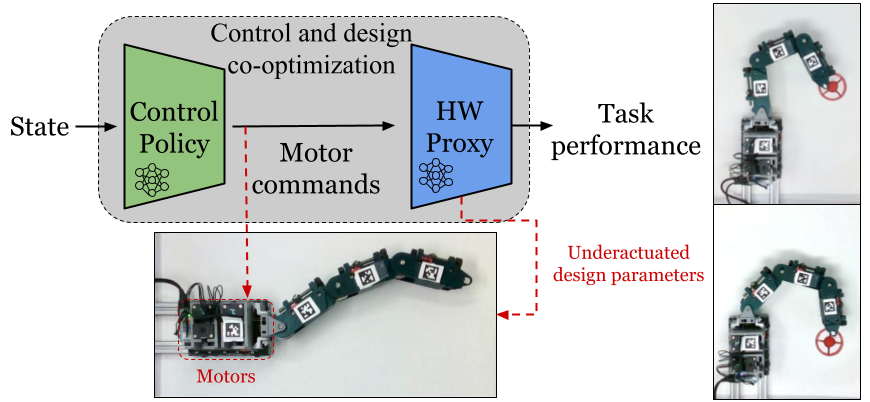
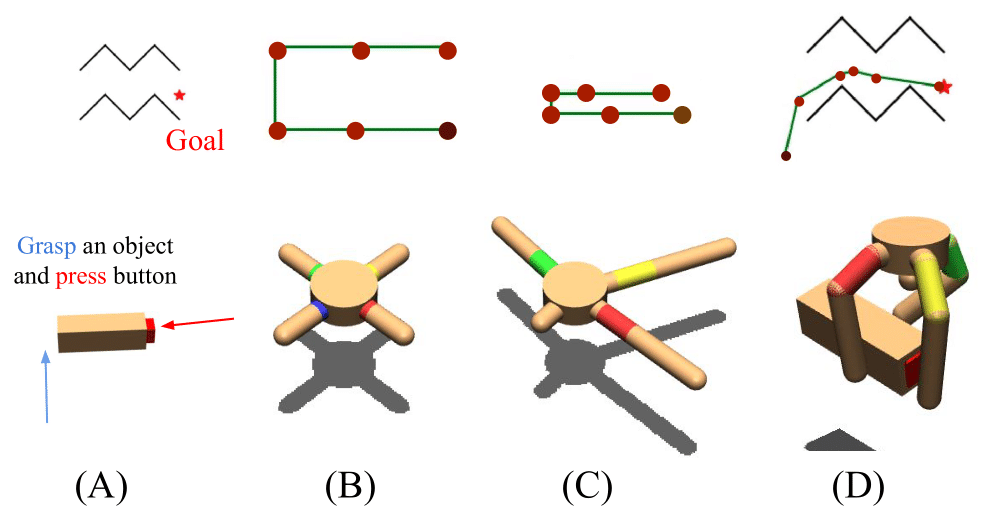
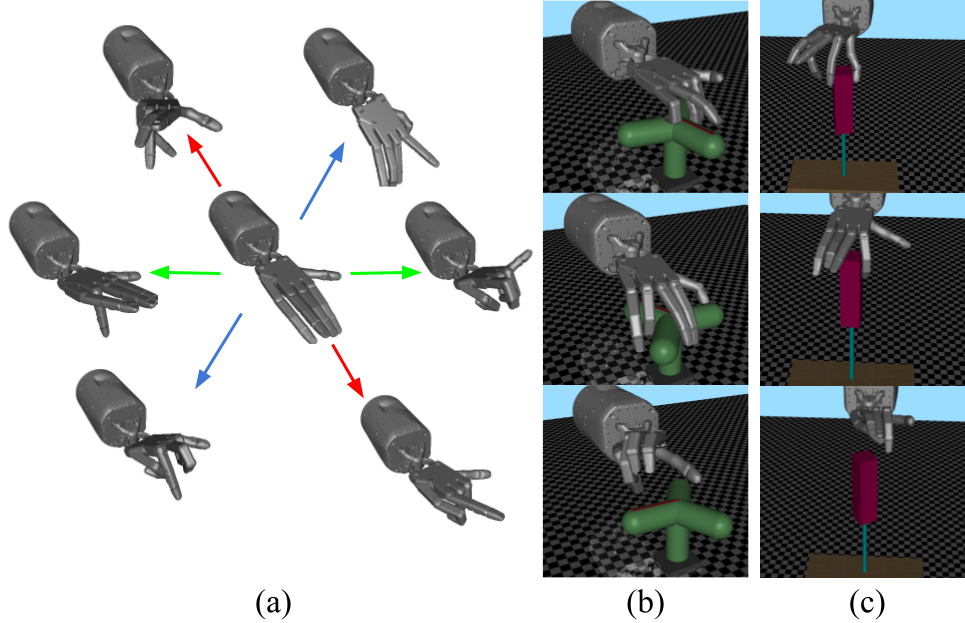
- Hardware design (e.g., manipulators, data collection systems, and contact sensors) and task-driven hardware optimization;
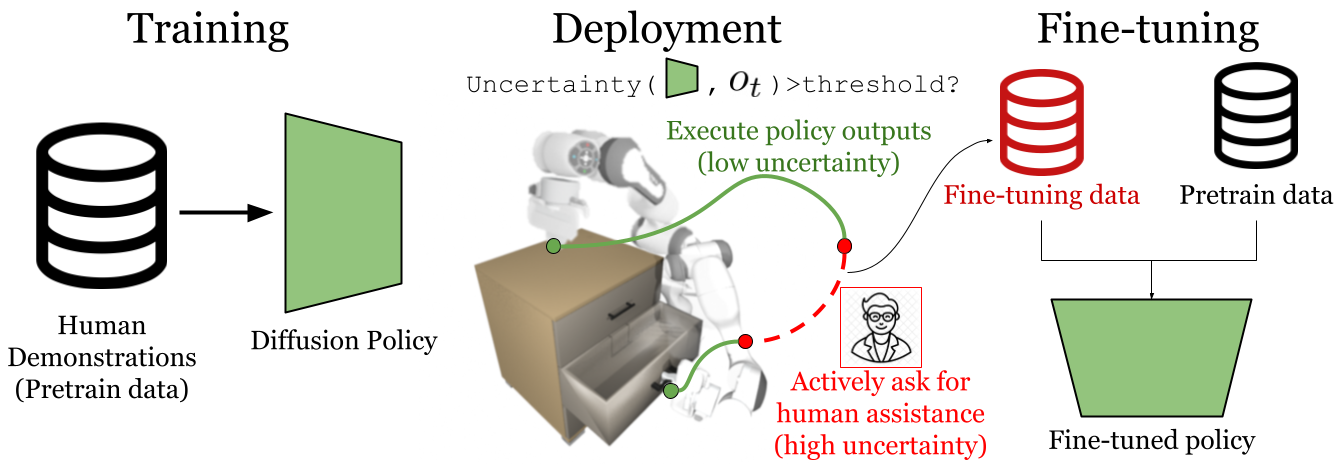
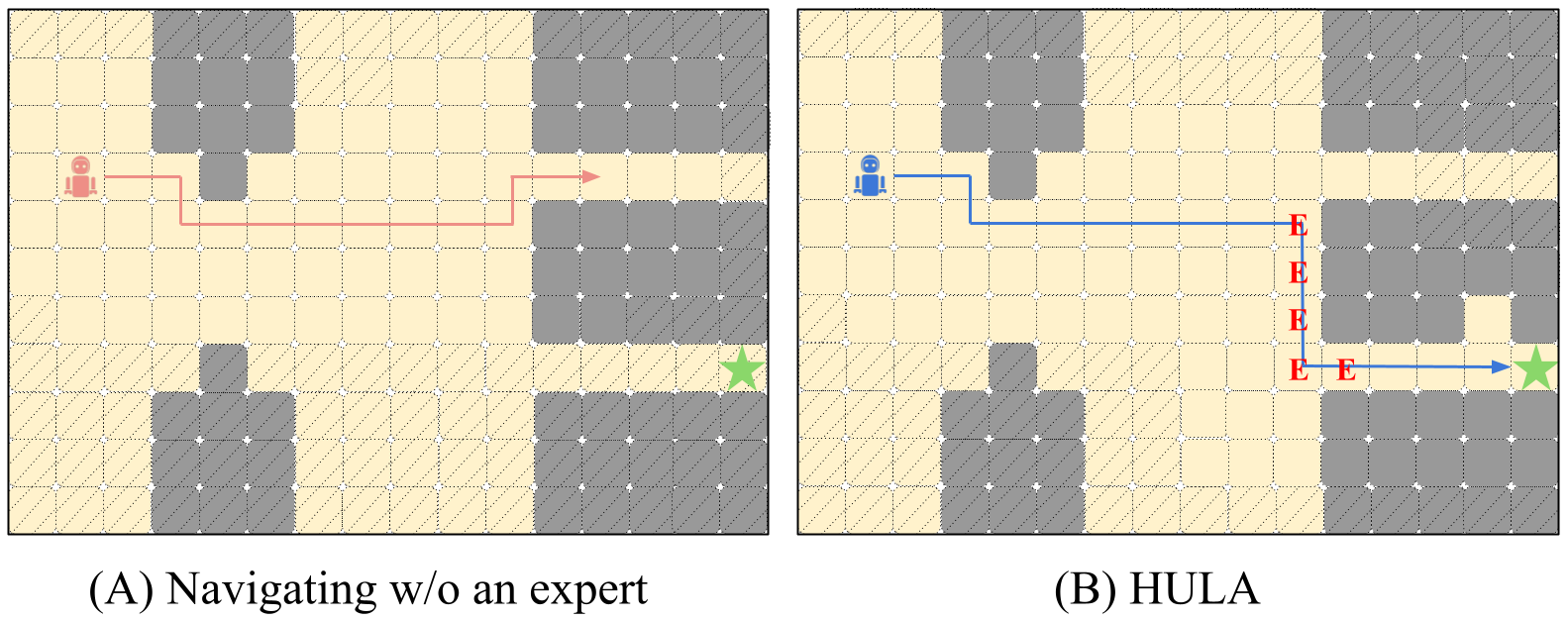
- Human-in-the-loop policy learning and deployment;







{kind=link}